
Storage Spaces es la evolución de Logical Disk Manager[EN] y nos permite agrupar discos físicos en volúmenes lógicos, de forma similar al LVM de Linux.
Hay múltiples configuraciones posibles, pero en este artículo nos vamos a centrar en la creación de un Storage Spaces con paridad simple, por qué tanta gente se queja de su rendimiento y qué podemos hacer para mejorarlo.
¿Qué es un Storage Space de paridad simple?
Es similar en concepto a un RAID5[EN]. En un RAID5 la información se distribuye entre los discos y en cada operación, uno de los discos contendrá la información de paridad. Esa información de paridad permitirá restaurar los datos si uno de los discos llegara a fallar. Al ser paridad simple, sólo uno de los discos puede ser recuperado, si fallara más de uno, sufriríamos pérdida de datos.
El número mínimo de discos en un Storage Spaces de paridad simple es 3. Esto es una cuestión matemática. Si un disco falla, la información puede recuperarse haciendo el XOR de la información disponible (mas info[EN]). El caso más simple sería una cosa así:
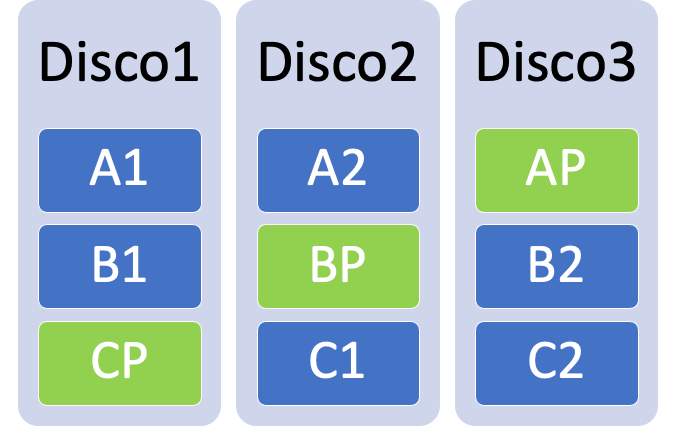
En cada pasada de escritura (stripe) Storage Spaces escribiría los datos (1 y 2) y además calcularía la paridad (P).
Lo primero que tenemos que tener claro es que, con tres discos, estamos utilizando el 66% para datos y el 33% para la paridad. Añadir otro disco haría que el porcentaje de uso subiera al 75%, ya que se usarían 3 discos para datos y 1 para paridad. Una vez más, esto no es nada nuevo y se comporta como RAID5.
A diferencia de RAID, Storage Spaces no está ligado a los discos duros físicos. En realidad, el diagrama anterior no es correcto, y donde dice Disco, debería decir Columna. Esas columnas son luego escritas en los discos duros físicos, lo que nos da más libertad y podemos hacer configuraciones independientemente del numero de discos. Hay limitaciones, como por ejemplo un mínimo de 3 discos para paridad simple. Esto es simplemente porque, aunque técnicamente se pudiera aplicar el esquema a un solo disco, no tendría ningún sentido… si se muere ese disco, se muere también la paridad. Si tenemos 2 discos, estaríamos haciendo mirroring con un XOR…. que tampoco tendría sentido.
¿Por qué es Storage Spaces lento en paridad?
Es lógico asumir que la escritura en un Storage Space con paridad es más lenta que en uno sin paridad ya que se debe calcular la paridad y escribirla. Sin embargo, muchos usuarios ven caídas[EN] de velocidad MUY superiores a las esperadas en otros sistemas de paridad como RAID5. Estamos hablando de discos HDD (vamos, de los de platos y aguja) que normalmente mantienen 100MB/sec rindiendo a unos pocos 30MB/sec.
El principal cuello de botella es el trabajo Storage Spaces tiene que hacer para convertir esas columnas a discos físicos. Para esto tenemos que entender 3 conceptos: stripe, interleave y columnas.
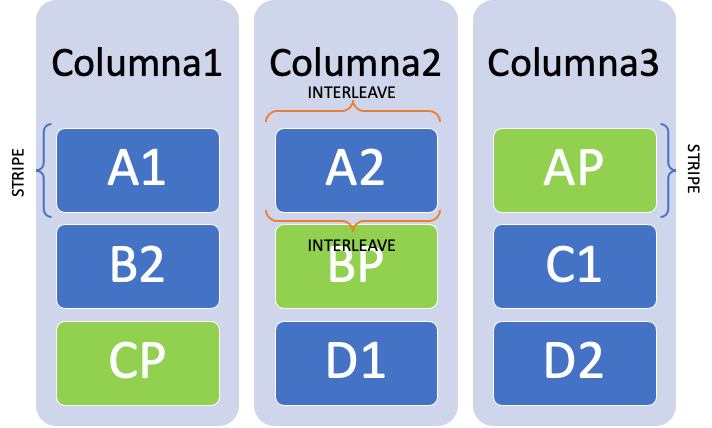
En cada escritura, deberíamos poder llenar una fila (strip) completa, lo que supone escribir dos bloques (interleave) de datos más uno de paridad que se calcula automáticamente. Cuando esto se lleva a los díscos físicos, los datos tienen que ser guardados dentro de una partición… y ahí es dónde está el problema. Storage Spaces nos da mucha flexibilidad a la hora de configurar cuántos discos y cómo los queremos usar, pero no todas las configuraciones tienen el mismo rendimiento.
El sistema de ficheros NTFS divide el espacio disponible entre clusters. Estos clusters tienen un tamaño fijo, determinado en el momento de formatear el volumen y es el mínimo de información que puede ser escrita al disco.
Supongamos que, en el ejemplo anterior, el Interleave es de 128KB, eso quiere decir que en cada stripe guardaríamos 256KB de datos y 128KB más de paridad. Cuando esos 256KB de datos se persistan en la partición NTFS, el sistema tiene que romperlos en el tamaño de cluster de la partición, que por defecto es de 4 u 8KB. Esa operación es costosa, y es la que produce las caídas de rendimiento y las quejas de los usuarios.
Sin embargo, podemos hacer que el tamaño de los datos de un stripe sea igual al tamaño del cluster de la particion NTFS, lo que permite que Storage Spaces no pierda el tiempo en operaciones inútiles. En el ejemplo anterior, para un sistema con 3 discos y paridad simple podríamos seguir la siguiente fórmula:
(número de columnas - 1) * interleave = tamaño del cluster Ahora bien, no todos los tamaños de cluster son aceptables. NTFS nos deja usar 4, 8, 16, 32 y 64KB. En nuestro ejemplo de 3 columnas, podríamos hacer que el interleave sea de 2KB y el cluster NTFS de 4KB, dándonos una alineación perfecta.
En mi caso, tengo 5 discos, con 5 columnas y un interleave de 16KB, por lo que he seleccionado un cluster size de 64KB.
¿Son todas las configuraciones posibles con buen rendimiento?
No, la división tamaño del cluster entre el numero de discos – 1 tiene que dar un numero entero positivo para que la alineación sea exacta… y buena suerte dividiendo 4, 8, 16, 32 o 64 entre 3 y que de un número exacto 🙂 Funcionar va a funcionar, pero con la caida de rendimiento que la mayoría experimenta.
El numero de discos no es (muy) relevante, Storage Spaces simplemente gestionará la información de modo que se usen todos los discos.
¿Por qué experimenta tanta gente mal rendimiento?
Valores por defecto. En NTFS el tamaño por defecto del cluster es de 4KB para discos pequeños y 16KB para discos grandes. El valor por defecto del interleave en Storage Spaces en parity es de 256KB (no he encontrado documentación oficial sobre este valor, es pura observación). Con esos valores no hay forma de alinear nada… así que la mayoría de la gente ve unas velocidades de unos 30MB/sec.
¿Por qué las transferencias son rápidas al principio y luego bajan?
Cache. Asumiendo que no se hayan configurado Tiers[EN], Windows maneja cache de forma transparente y, parece ser, que en la mayoría de los casos asigna 1GB de cache. Es decir, el primer GB estará acelerado y a partir de ahí veremos la velocidad del Storage Spaces, que suele rondar los 30MB/sec para discos HDD.
¿Cómo creo un Storage Spaces con buen rendimiento?
Lo primero es obtener el número de columnas correcto usando la fórmula listada antes. Después, deberemos crear el volumen desde PowerShell, porque la GUI no nos deja configurar los valores y hará lo que quiera, que rara vez es la configuración óptima.
En mi caso, con 5 discos que tengo en un Storage Spaces Pool, he creado el siguiente disco virtual:
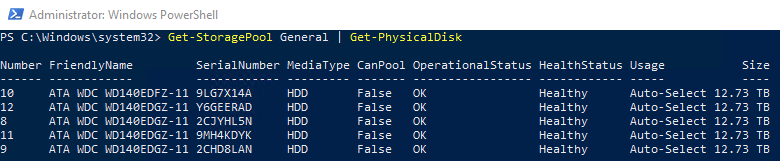

Con un mandato similar a este:
New-VirtualDisk -StoragePoolFriendlyName “PoolQueTengamos” -ProvisioningType Fixed -Interleave 16KB -FriendlyName “NorthwindVD” -UseMaximumSize -ResiliencySettingName Parity -NumberOfColumns 5Después, he formateado el volumen como NTFS con cluster size de 64KB. He elegido un tamaño de cluster grande porque uso ese pool para escribir archivos grandes, por lo que un tamaño grande resulta en menos operaciones y poco espacio desperdiciado.

El resultado
Una vez el disco virtual está creado con el interleave adecuado y el volumen formateado con un tamaño de cluster que se alinee, la velocidad aumenta de unos 30MB/sec a unos 350MB/sec:

Esto no quiere decir que Storage Spaces sea la mejor opción para usar en paridad, pero desde luego no tiene por qué comportarse tan mal como muchos usuarios experimentan.